我们在数据结构的学习中,都接触过二叉树。二叉树常用的遍历方法包括:前序遍历、中序遍历、后序遍历以及层次遍历。其中前三种遍历方法均可以通过递归或者迭代实现。递归实现难度较小,而且写出来的代码简洁明了;迭代实现起来则具有一定难度。在这篇文章中,我就来总结一下利用迭代遍历二叉树的方法。
一、前序遍历
二叉树的前序、中序和后序遍历都是通过栈来实现的,而前序遍历则是其中最简单的。所谓前序遍历,指的是对于每个结点,先访问该结点本身,然后访问左子树,最后访问右子树。为了进行前序遍历,我们初始化一个空栈存储二叉树的结点。首先令根结点入栈。每当栈不为空,弹出栈顶的结点并访问该结点,然后依次将其右儿子、左儿子入栈(如果不为NULL)。注意入栈的顺序是先右儿子,再左儿子。
Preorder Traversal
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| vector<int> preorderTraversal(TreeNode* root) {
vector<int> res;
if(!root)
return res;
stack<TreeNode*> nodeStack;
nodeStack.push(root);
while(!nodeStack.empty()){
TreeNode* node = nodeStack.top();
nodeStack.pop();
res.push_back(node->val);
if(node->right)
nodeStack.push(node->right);
if(node->left)
nodeStack.push(node->left);
}
return res;
}
|
二、中序遍历
所谓中序遍历,指的是对于每个结点,先访问左子树,然后访问该结点本身,最后访问右子树。为了进行中序遍历,我们需要维持两个栈,一个栈存储二叉树的结点,另一个栈则是标记栈,存储结点栈中相应结点的标记,标记的取值可能为0或1。
首先,我们令根结点入栈(标记为0)。每当栈不为空,我们弹出栈顶结点及其标记:如果该结点的标记为0,则令该结点再次入栈(标记为1),并且如果该结点有左儿子,将其左儿子入栈(标记为0);如果该结点的标记为1,则访问该结点,并且如果该结点有右儿子,将其右儿子入栈(标记为0)。
Inorder Traversal
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
if(!root)
return res;
stack<TreeNode*> nodeStack;
stack<int> markStack;
nodeStack.push(root);
markStack.push(0);
while(!nodeStack.empty()){
TreeNode* node = nodeStack.top();
int mark = markStack.top();
nodeStack.pop();
markStack.pop();
if(mark == 0){
nodeStack.push(node);
markStack.push(1);
//Left child:
if(node->left){
nodeStack.push(node->left);
markStack.push(0);
}
}else{
res.push_back(node->val);
//Right child:
if(node->right){
nodeStack.push(node->right);
markStack.push(0);
}
}
}
return res;
}
|
三、后序遍历
所谓后序遍历,指的是对于每个结点,先访问左子树,然后访问右子树,最后访问该结点本身。后序遍历的实现思路和中序遍历类似,仍然是维持一个结点栈和一个标记栈,不同之处在于标记的取值可能为0、1或2。
首先,我们令根结点入栈(标记为0)。每当栈不为空,我们弹出栈顶结点及其标记:如果该结点的标记为0,则令该结点再次入栈(标记为1),并且如果该结点有左儿子,将其左儿子入栈(标记为0);如果该结点的标记为1,则令该结点再次入栈(标记为2),并且如果该结点有右儿子,将其右儿子入栈(标记为0);如果该结点的标记为2,则访问该结点。
Postorder Traversal
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| vector<int> postorderTraversal(TreeNode* root) {
vector<int> res;
if(!root)
return res;
stack<TreeNode*> nodeStack;
stack<int> markStack;
nodeStack.push(root);
markStack.push(0);
while(!nodeStack.empty()){
TreeNode* node = nodeStack.top();
int mark = markStack.top();
nodeStack.pop();
markStack.pop();
if(mark == 0){
nodeStack.push(node);
markStack.push(1);
//Left child:
if(node->left){
nodeStack.push(node->left);
markStack.push(0);
}
}else if(mark == 1){
nodeStack.push(node);
markStack.push(2);
//Right child:
if(node->right){
nodeStack.push(node->right);
markStack.push(0);
}
}else
res.push_back(node->val);
}
return res;
}
|
另外需要注意的是,通过一棵二叉树的前序与中序,或者中序与后序遍历序列是可以重建这棵二叉树的。比如一棵二叉树的前序与中序遍历序列如下:
前序遍历序列:a,b,e,c,f,g;
中序遍历序列:b,e,a,f,c,g。
我们知道,前序遍历序列的结点顺序为根结点、左子树、右子树;中序遍历为左子树、根结点、右子树;后序遍历则为左子树、右子树、根结点。通过这个结论,我们可以知道结点a为二叉树的根结点,所以在中序遍历序列中,位于a前面的序列b,e就是左子树的中序遍历序列,位于a后面的序列f,c,g则是右子树的中序遍历序列。另外我们可以确定,左右子树的大小分别为2和3,所以在前序遍历序列中,a后面的2个结点b,e就是左子树的前序遍历序列,再后面的3个结点c,f,g就是右子树的前序遍历序列。
然后我们对左右子树分别进行递归调用,即可重建这棵二叉树。
四、层次遍历
如果说前序遍历类似于图的深度优先搜索,那么层次遍历则类似于广度优先搜索。层次遍历指的是按照结点所在层,从根结点开始逐一访问。不同于之前几种遍历方法利用栈来实现,层次遍历是利用队列来实现的。首先我们初始化一个空队列并令根结点进队。每当队列不为空,使队列最前端的结点出队并且访问该结点,然后将该结点的左右儿子依次进队。
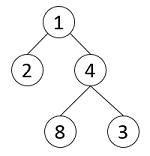
扩展:输入一棵二叉树,将其层次遍历序列输出到vector中,不同层的结点需要输出到不同的vector中。比如对于如下图所示的二叉树,层次遍历的结果应该是[[1],[2,4],[8,3]]。
答案:上面的题目要求我们在层次遍历的基础上,将不同层的结点加以区分。我们可以利用两个队列交替放置不同层的结点,也就是说当队列A中的一个结点出队时,我们将其左右儿子加入到队列B中,反之亦然。这样,与当前结点同一层的结点就会出现在同一个队列中,而当前结点的上层或下层结点就会在另一个队列中出现,达到了区分不同层结点的目的。
Level Order Traversal
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> res;
if(!root)
return res;
queue<TreeNode*> q[2];
int dep = 0;
q[dep].push(root);
while(!q[dep].empty()){
vector<int> tmp;
while(!q[dep].empty()){
TreeNode *p = q[dep].front();
q[dep].pop();
tmp.push_back(p->val);
if(p->left)
q[dep^1].push(p->left);
if(p->right)
q[dep^1].push(p->right);
}
res.push_back(tmp);
dep ^= 1;
}
return res;
}
|