并查集是一种非常精巧而实用的数据结构,它可以处理一些不相交集合的合并与查询问题。并查集的用途有求连通子图、求最小生成树(Kruskal算法)、求最近公共祖先等。本文就通过hihoCoder上的一道题目“无间道之并查集”,来介绍一下并查集这种数据结构。
一、题目
背景
这天天气晴朗、阳光明媚、鸟语花香,空气中弥漫着春天的气息……额,说远了,总之,小Hi和小Ho决定趁着这朗朗春光出去玩。但是刚刚离开居住的宾馆不久,抄近道不小心走入了一条偏僻小道的小Hi和小Ho就发现自己的前方走来了几个彪形大汉,定睛一看还都是地地道道的黑人兄弟!小Hi和小Ho这下就慌了神,捡肥皂事小,这一身百把来斤别一不小心葬身他乡可就没处说去了。
就在两人正举足无措之时,为首的黑叔叔从怀里掏出了一件东西——两张花花绿绿的纸,分别递给了小Hi和小Ho。小Hi和小Ho接过来,只见上面写道:“本地最大的帮派——青龙帮,诚邀您的加入!”下面还详细的列出了加入青龙帮的种种好处。
于是两人略感心安,在同黑叔叔们交谈一番之后,已是均感相见恨晚。同时,在小Hi和小Ho表示自己不日便将回国之后,黑叔叔们也没有再提加入帮派之事,但是那为首的黑叔叔思索一会,开口道:“我现在有一个难题,思索了很久也没法子解决,既然你们俩都是高材生,不如来帮我看看。”
小Hi和小Ho点了点头表示没问题,于是黑叔叔继续说道:“这个问题是这样的,我们帮派最近混进了许多警察的卧底,但是在我们的调查过程中只能够知道诸如‘某人和另一个人是同阵营的’这样的信息,虽然没有办法知道他们具体是哪个阵营的,但是这样的信息也是很重要的,因为我们经常会想要知道某两个人究竟是不是同一阵营的。”
小Hi和小Ho赞同的点了点头,毕竟无间道也都是他们看过的。
黑叔叔接着说道:“于是现在问题就来了,我希望你们能写出这样一个程序,我会有两种操作,一种是告诉它哪两个人是同一阵营的,而另一种是询问某两个人是不是同一阵营的……既然你们就要回国了,不如现在就去我们帮派的总部写好这个程序再走吧。”
为了生命安全与……小Hi和小Ho都不得不解决这个问题!
输入与输出
输入数据的第一行为一个整数N,表示黑叔叔总共进行的操作次数。
输入数据的第二至N+1行,每行分别描述黑叔叔的一次操作,其中第i+1行为一个整数op_i和两个由大小写字母组成的字符串Name1_i、Name2_i。op_i只可能为0或1。当op_i==0时,表示黑叔叔判定Name1_i和Name2_i是同一阵营的;当op_i==1时,表示黑叔叔希望知道Name1_i和Name2_i是否为同一阵营的。
输出:对于黑叔叔每次op_i==1的操作,输出一行,表示查询的结果:如果根据已知信息(即这次操作之前的所有op_i==0的操作),可以判定询问中的两个人是同一阵营的,则输出yes,否则输出no。
注意:数据中所有涉及的人物中不存在两个名字相同的人(即姓名唯一地确定了一个人),对于所有的i,满足Name1_i和Name2_i是不同的两个人。
| 样例输入 | 样例输出 |
|---|---|
10 | yes |
二、并查集简介
并查集即一个或多个不相交的集合,我们从每个集合中选出一个元素作为代表,来表示这个集合。一般情况下,我们不关心每个集合具体包含哪些元素;也不关心每个集合的代表具体是哪个元素。我们所关心的并查集的基本操作主要包含合并(Union)和查询(Find)操作。其中查询操作是给定一个元素,返回该元素所在集合的代表元素;合并操作则是给定两个元素,将它们所在的集合合并为一个整体。
我们可以用一个森林来表示并查集,森林中的每棵树代表并查集中的一个集合,树中每个结点表示一个元素,根结点则是这个集合的代表元素。初始状态下,每个结点单独成为一个集合,即每个结点的代表结点均为它自己,如图所示:

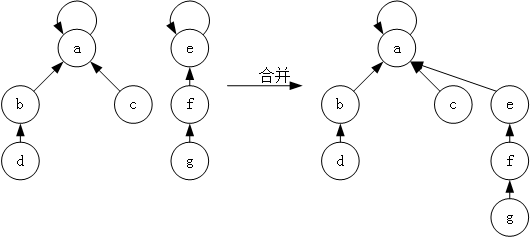
并查集的合并操作则是将一棵树的根结点指向另一棵树的根结点。如图所示:
而在C++中,我们可以用一个map或者unordered_map来实现并查集。其中,键代表一个结点的名字,值表示其代表结点的名字。这样,我们可以为上面的问题建立一个数据结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 | |
三、查询操作
find操作的实现是显而易见的:判断当前元素的代表结点是不是它自己,如果是,返回它自己;如果不是,则对其代表结点递归调用find函数。这样的思路写成伪代码如下:
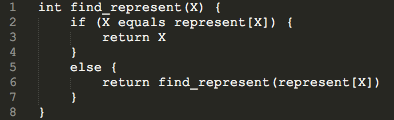
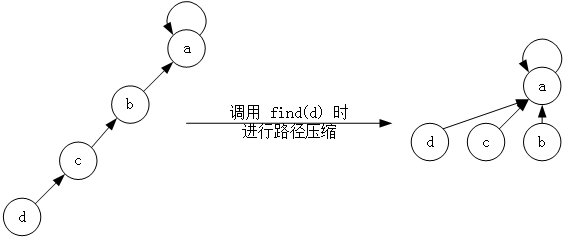
但是这种思路有一个缺陷,它的平均时间复杂度为树的高度。为了提高查询操作的效率,我们可以在查询的过程中改变树的结构:如果我们求解出了X所在集合的代表元素是X_r的话,我们可以直接令represent[X]=X_r。这样,下一次再对X进行查询时,效率就会高很多。这种操作会在查询时令查询路径上经过的每一个结点都直接指向根结点,就像把整条路径压缩了一样,所以被称为路径压缩,如图所示:
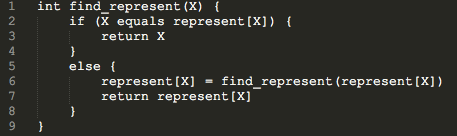
实现路径压缩的伪代码如下:
四、合并操作
union操作需要输入两个元素name1和name2,我们首先调用find找到这两个元素的代表元素repName1和repName2,然后令repName1的代表元素等于repName2即可。
当然这一步也可以做一些优化:假设两个元素对应的树高度分别为3和4,如果我们将第二棵树合并到第一棵树上,那么最终得到的树的高度就是5;如果反过来合并,那么得到的树的高度就是4。为了让我们每次合并之后得到的树的高度都是最小的,我们需要将高度较小的树合并到高度较大的树上面。在并查集中,我们通常将树高度的上界称为秩(rank),这种将秩较小的树合并到秩较大的树上的方法,称为按秩合并。
在下面的代码中,我们利用unordered_map<string, int> rank来记录每个结点的秩,然后根据秩的大小关系决定合并操作的方法:
1 2 3 4 5 6 7 8 | |